
Research
I study computational linguistics using techniques from cognitive science, machine learning, and natural language processing. I am particularly interested in how people and machines learn and represent the structure of language: What types of computational machinery can explain the linguistic abilities of humans, and how can we instantiate these abilities in machines? Much of my research focuses on neural network language models: What can the success of such systems tell us about human language, and how can ideas from linguistics and cognitive science help us to understand such systems? I am also interested in how we can combine neural networks with other modeling approaches, such as Bayesian models. Occasionally I run human experiments studying how people learn language. Below are some of the more specific topics that I work on.
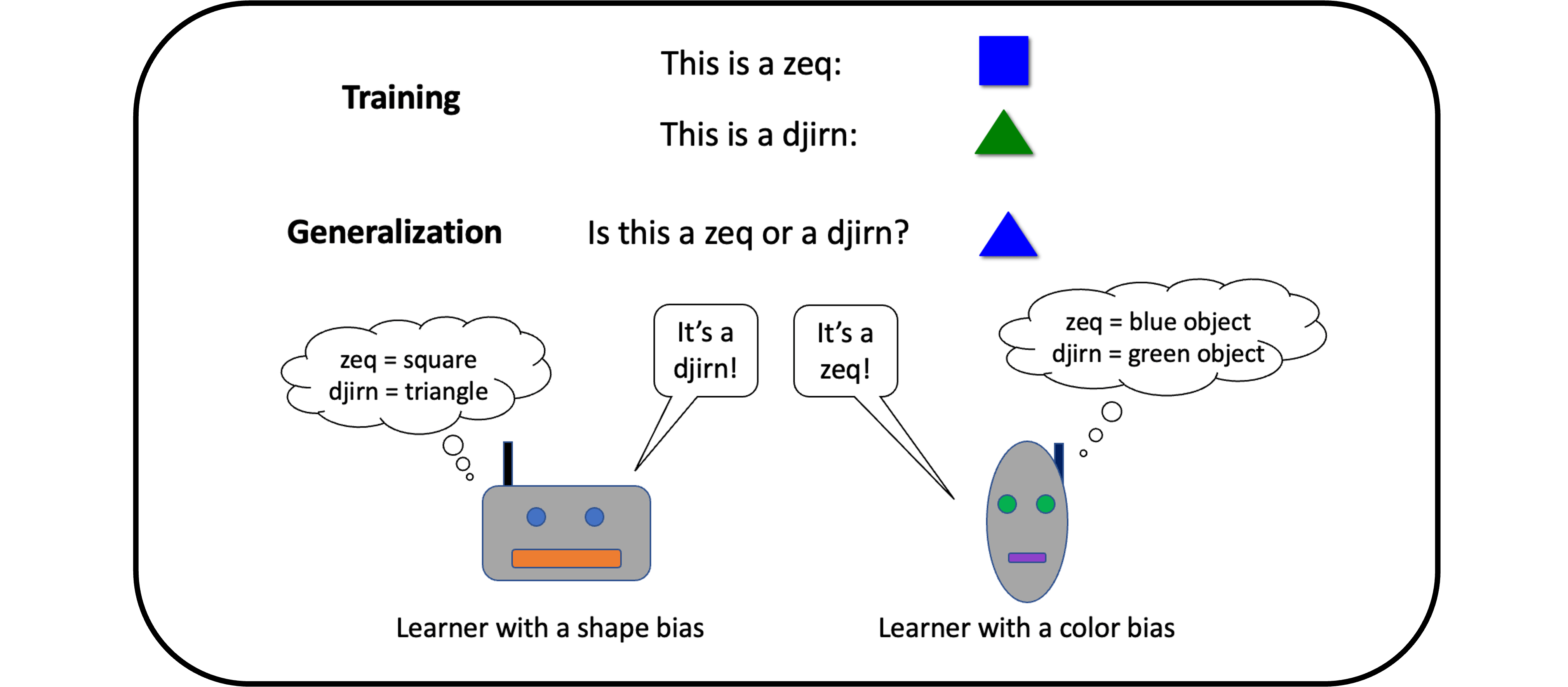

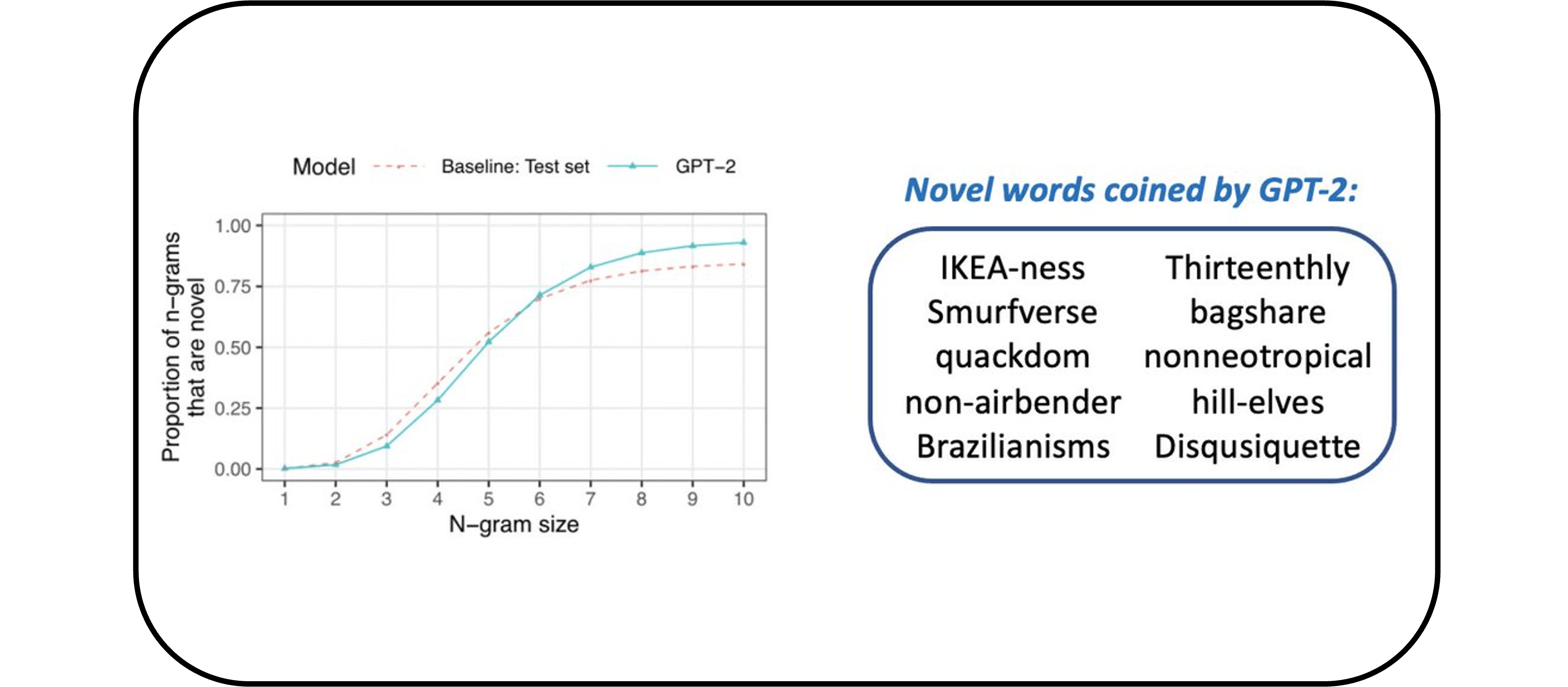
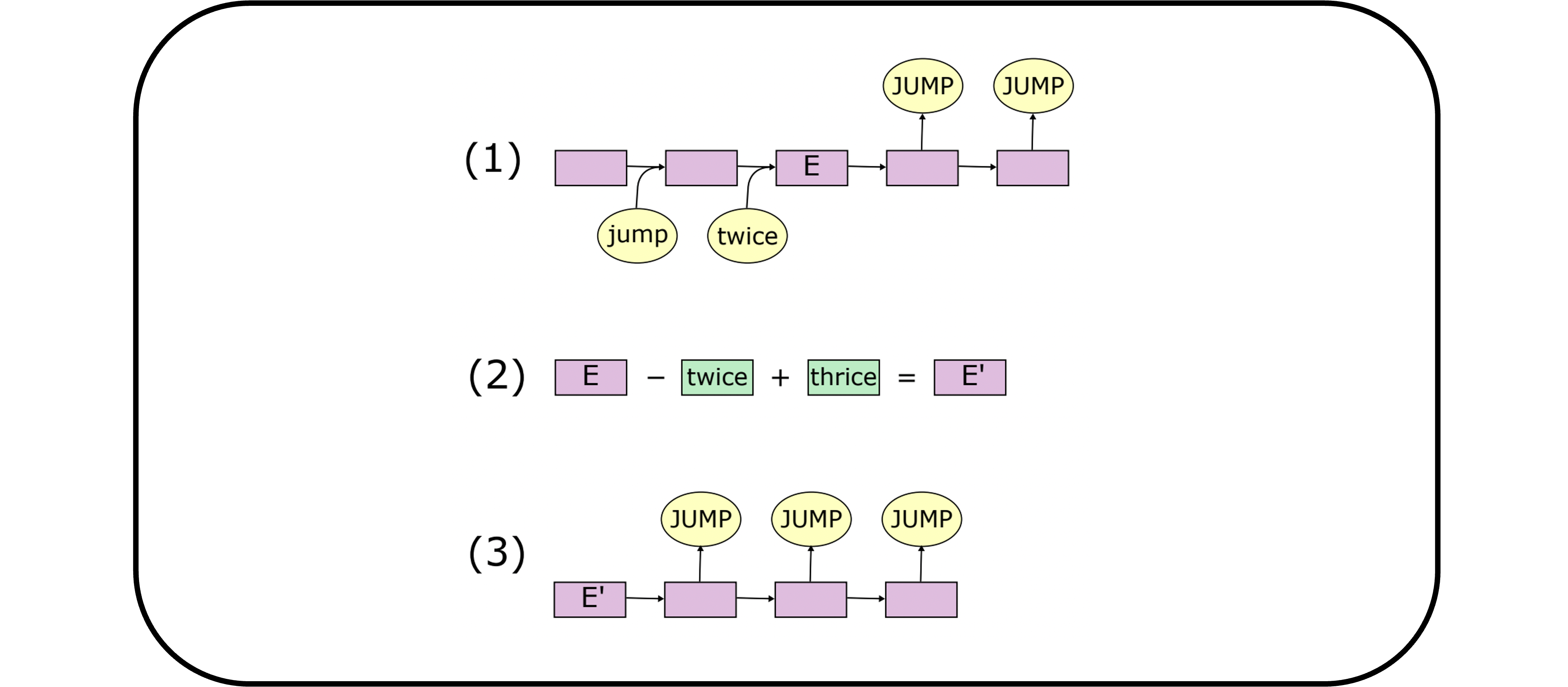
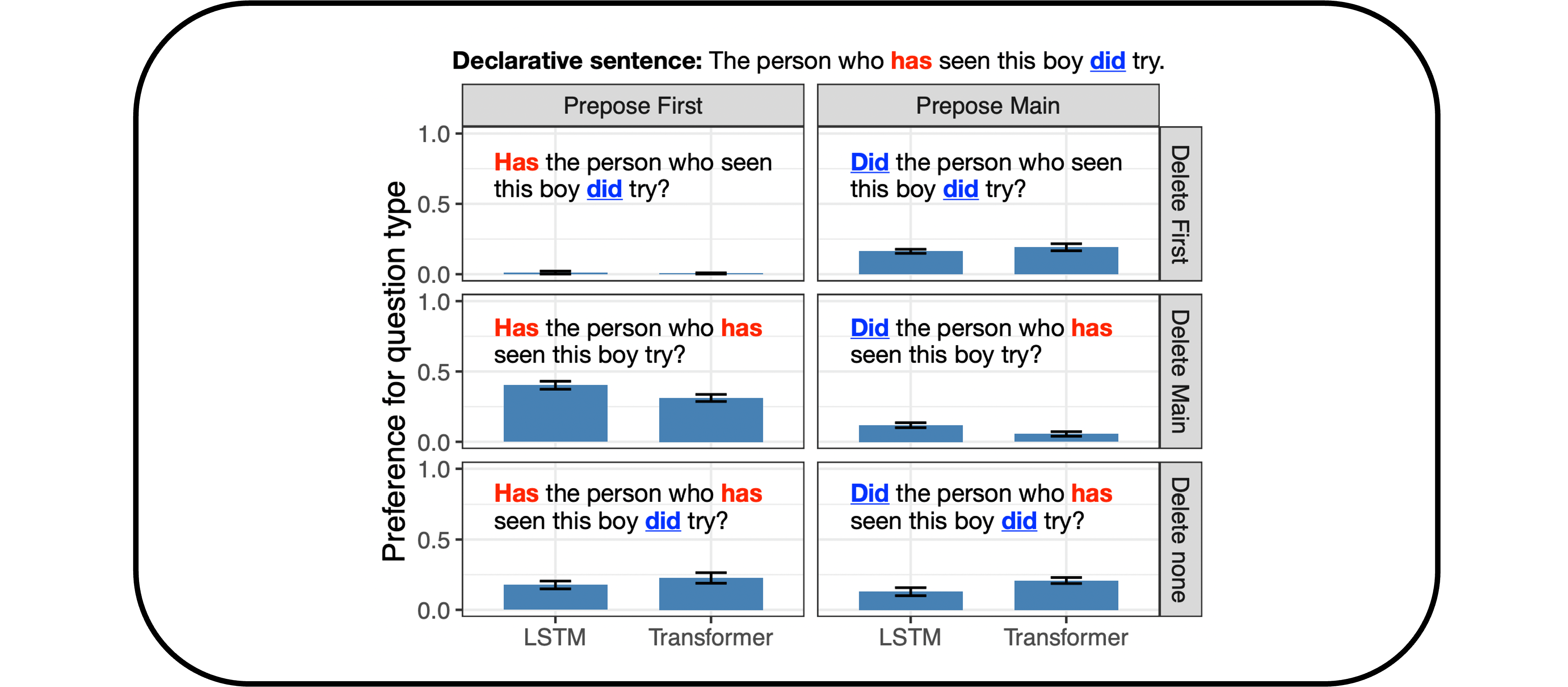

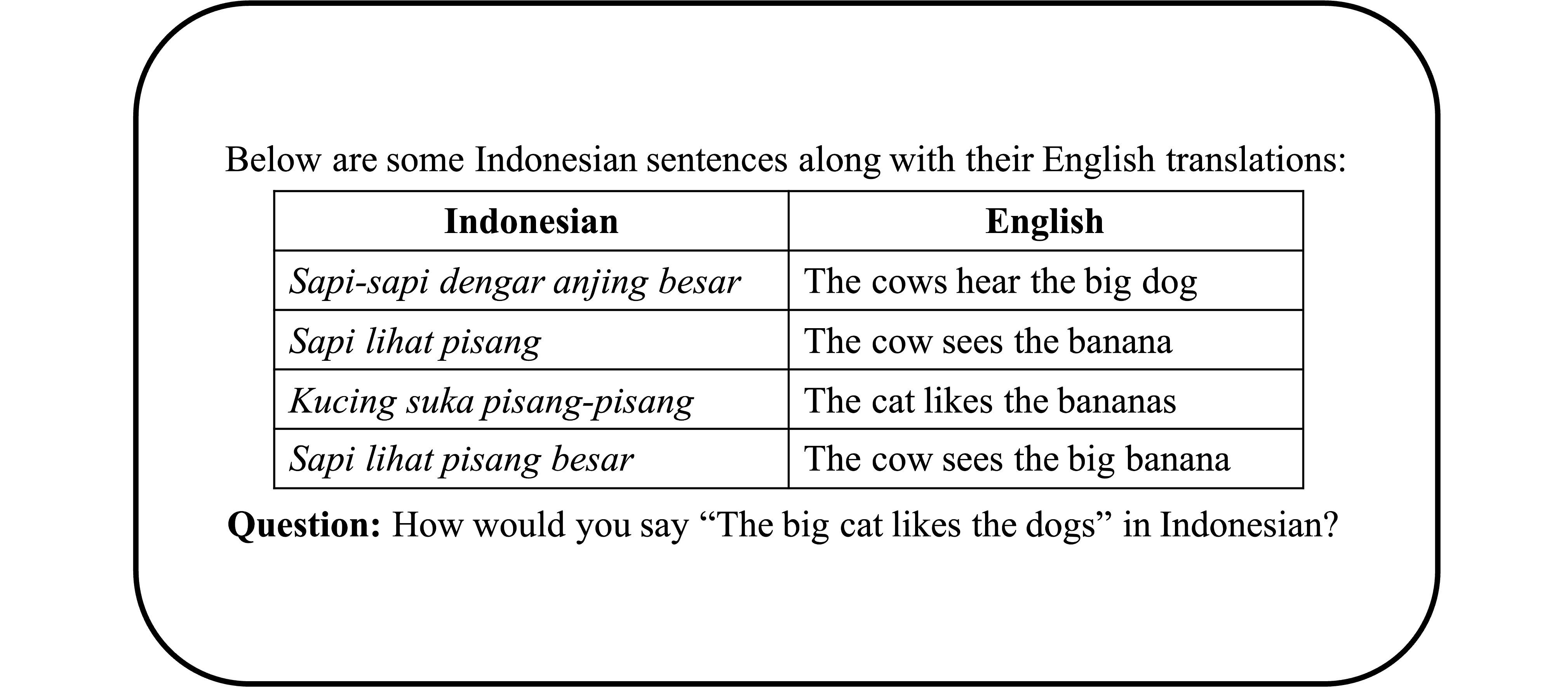
Computationally modeling language learning: One of the most remarkable aspects of human cognition is our ability to learn language from so little data. Current systems in artificial intelligence are trained on hundreds of billions of words, yet humans can aquire a language from only fifty million words—thousands of times less data! We can also apply what we have learned in novel scenarios that seem to go far beyond our experience. Suppose you’ve heard the phrase the hat is molistic. You would know immediately that it is also grammatical to say the molistic hat—that is, you can readily generalize in a way that puts molistic in a position where it has never appeared before, namely in front of a noun. At the same time, there are interesting constraints on how people generalize: even when they have seen the sentence the baby is asleep, most English speakers think it sounds strange to say the asleep baby.
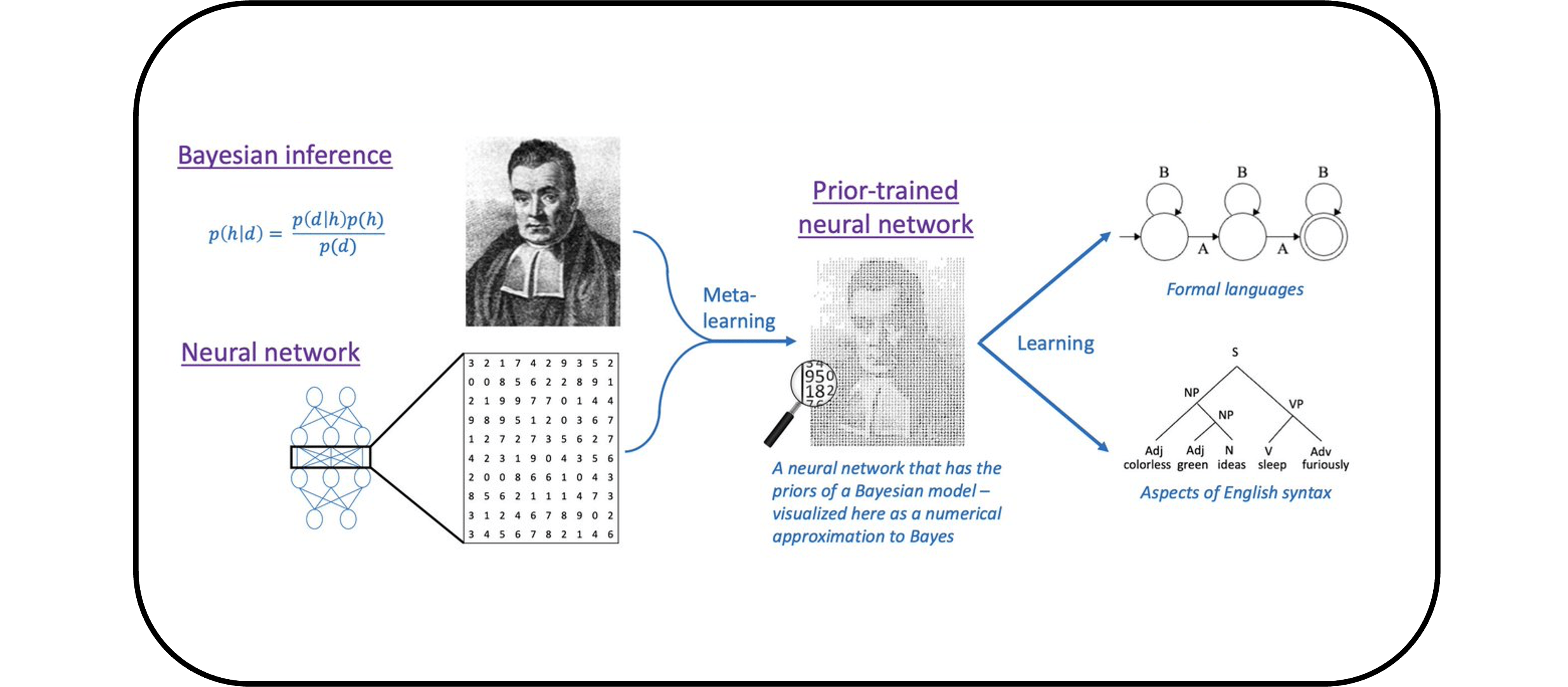
How can we explain the impressive, nuanced ways in which people learn and generalize? This question is of central importance in linguistics; answering it may also help us to build machines that can learn as rapidly and robustly as humans do. Some of our work in this area involves testing which types of neural network models can generalize in human like ways, developing an approach for combining Bayesian models and neural networks, and running human experiments to test how people generalize when learning syntactic phenomena. [Technical keywords: inductive bias; the poverty of the stimulus; nativism/empiricism; meta-learning]
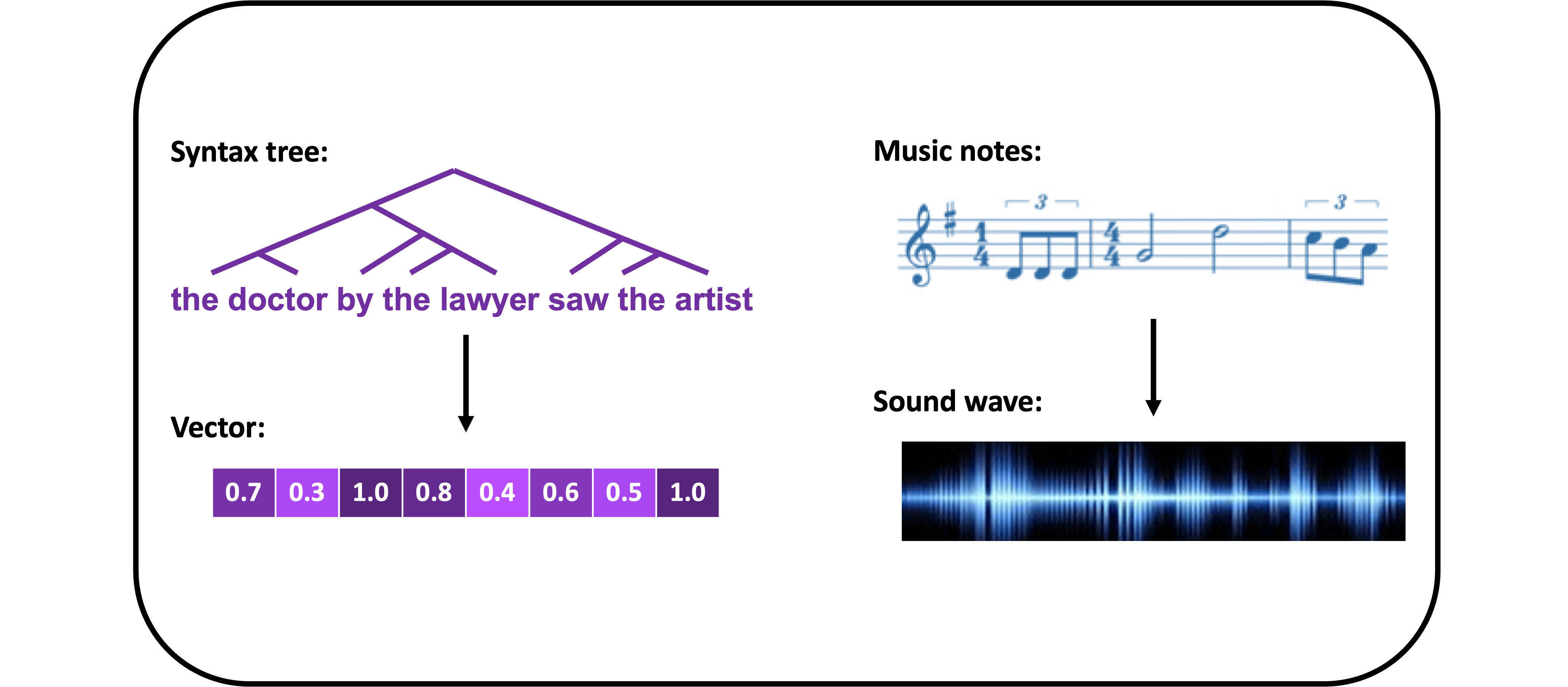
Bridging the divide between vectors and symbols: In addition to developing computational characterizations of learning, I am also interested in characterizing the computational nature of representations. For millennia, linguists have analyzed language using symbolic structures, in which discrete units (such as words) are combined in highly structured ways (such as syntax trees). However, the most successful systems for processing language in artificial intelligence are neural networks (such as ChatGPT), which instead represent information using vectors of continuous numbers. Such vectors look nothing like the structured symbolic representations that are standard in linguistics, so how can they encode the structure of language? Answering this question is important for understanding how neural networks operate and how they relate to linguistic theory. Further, it may ultimately lead to insight about how language is represented in the brain, as the brain is also a type of neural network (albeit one that is different in many ways from the networks used in AI), meaning that the brain’s ability to represent language is just as puzzling as the ability of AI systems to do this. Our work in this area involves testing the hypothesis that neural networks implicitly construct systematic vector representations that capture compositional structure, and showing how encouraging such structure can improve neural network performance. [Technical keywords: compositionality; Tensor Product Representations]
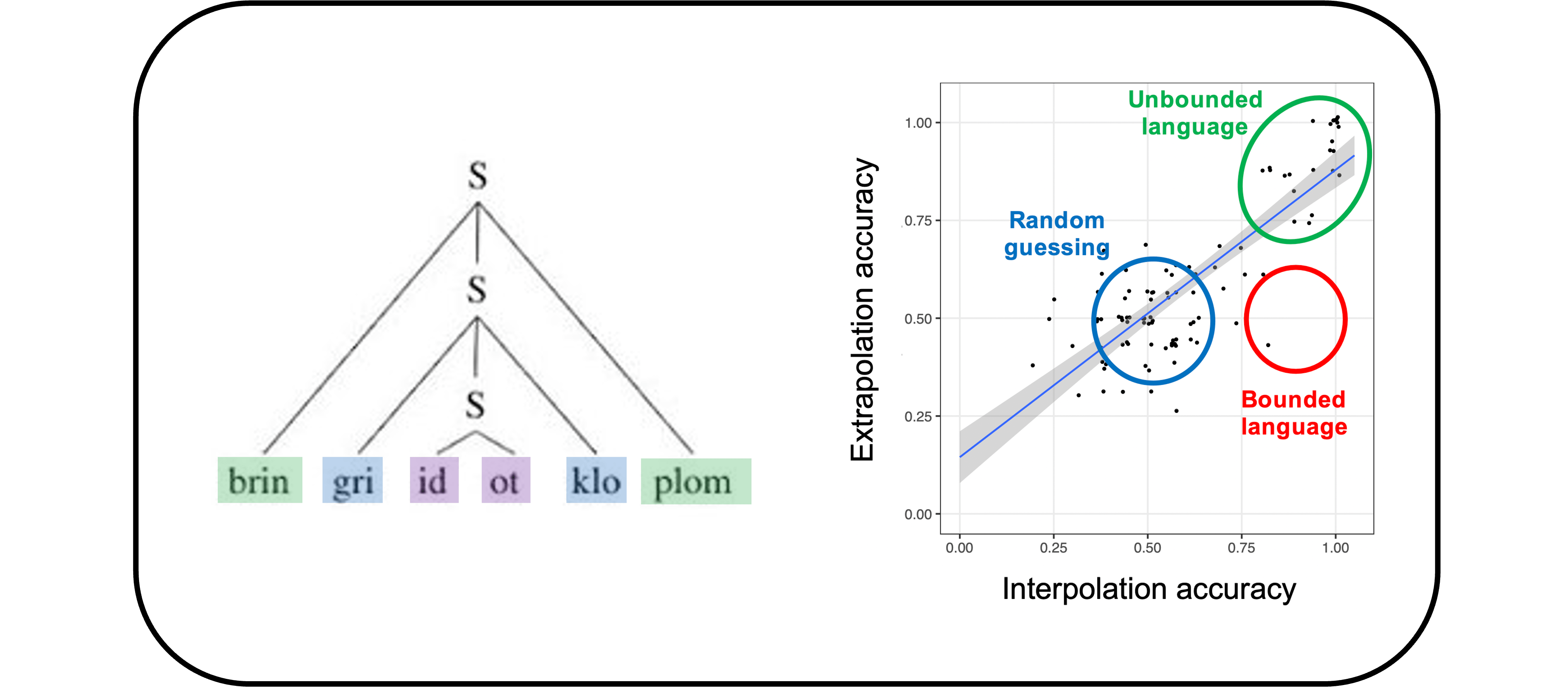
Rethinking how we evaluate systems in artificial intelligence: Pervading all of this work is the need to evaluate computational models of language: in order to reason about what a machine has learned or is representing, we need to determine which aspects of language the machine has captured (or failed to capture). The standard approach for evaluating systems in artificial intelligence is to collect a set of examples and then partition it randomly into some examples that are used for training and others that are used for testing. There is an important shortcoming of this approach: a system can succeed on a randomly-partitioned test set by learning shallow heuristics that succeed for frequent example types but fail on rarer cases. I am interested in developing more targeted approaches for evaluation—approaches that are driven by hypotheses about what strategies a system may be using and that use controlled stimuli to disentangle these possible strategies (e.g., is the system processing sentences in a way that factors in the sentence’s syntactic structure, or does it instead treat the sentence as an unordered bag of words?) Using this general paradigm, we have developed evaluations that illustrate ways in which a model’s training task can explain model shortcomings, evaluations that test for the use of brittle syntax-insensitive heuristics, evaluations that test for model variability across random reruns, and evaluations that explore the influence of training data memorization on model performance.