Does Syntax Need to Grow on Trees? Sources of Hierarchical Inductive Bias in Sequence-to-Sequence Networks
Tom McCoy, Robert Frank, Tal Linzen
This page provides the full data for the paper found here. The code is available here.
1. Introduction: Inductive biases
Consider the miniature experiment below: Two learners are shown a set of training examples which are consistent with multiple possible rules. When the learners are asked to generalize to a novel example, their responses reveal that they have learned different rules. These differences cannot be due to the training data, because both learners have seen the same training data. Instead, the differences must be due to some property of the learners. The properties that determine how a learner generalizes from ambiguous data are called inductive biases. In this case, the learner on the left has an inductive bias favoring generalizations based on shape, while the learner on the right has an inductive bias favoring generalizations based on color.
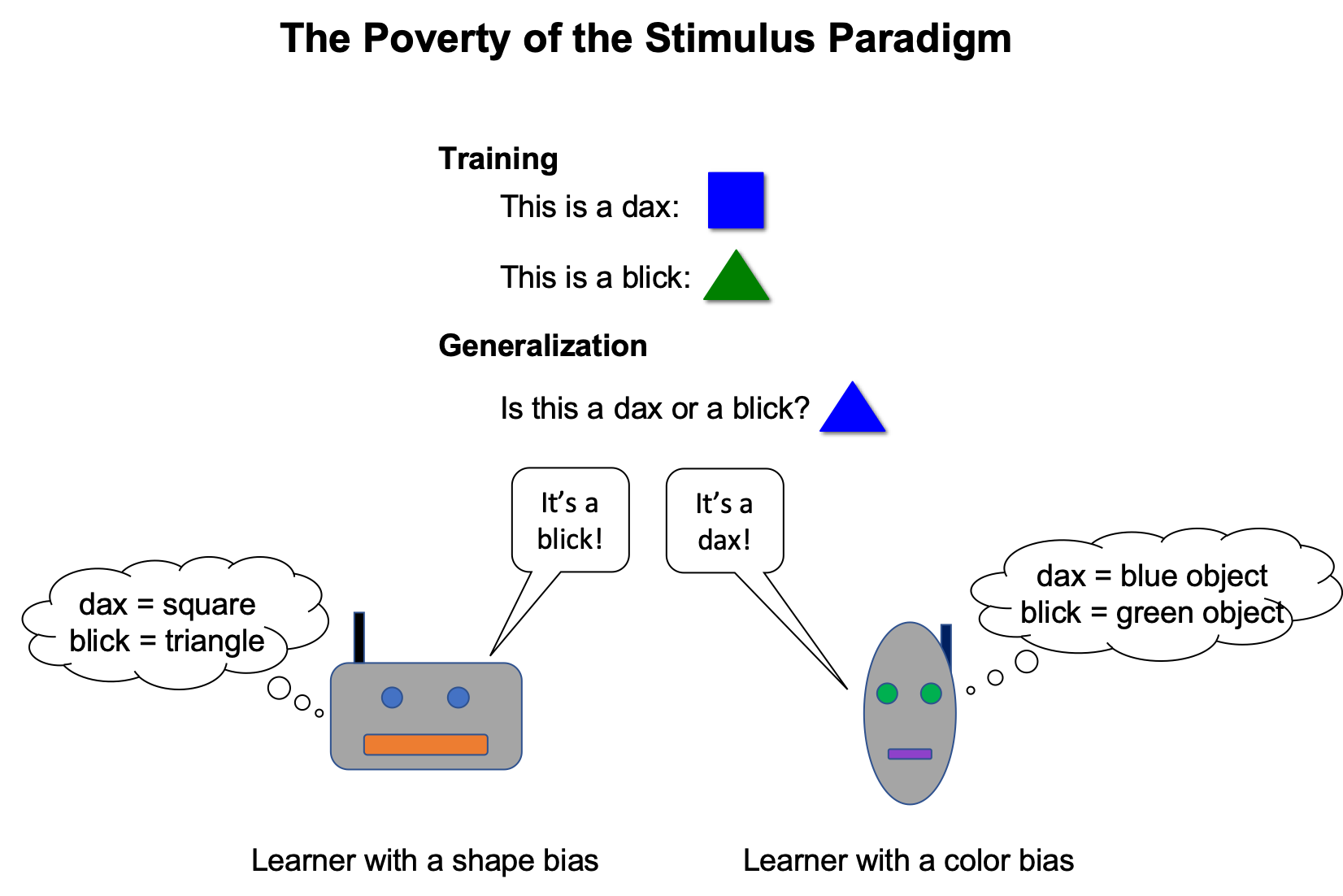
What properties of a learner cause it to have one inductive bias rather than another? We study this question using several types of sequence-to-sequence neural networks, which are models that transform one sequence into another (in our case, the models are transforming one sentence into another sentence). We focus on one particular bias, namely a bias for generalizations based on hierarchical structure, since such a hierarchical bias has long been argued to play a central role in children's acquisition of language. Understanding this bias can therefore lend insight into human language acquisition and can also help us create models of language that generalize better to novel syntactic structures.
To investigate which types of models have a hierarchical bias, we use two tasks based on English syntax: question formation (that is, mapping a declarative sentence to a yes/no question) and tense reinflection (that is, mapping a past-tense sentence to a present-tense sentence). The following diagrams illustrate the experimental setups for these two tasks:
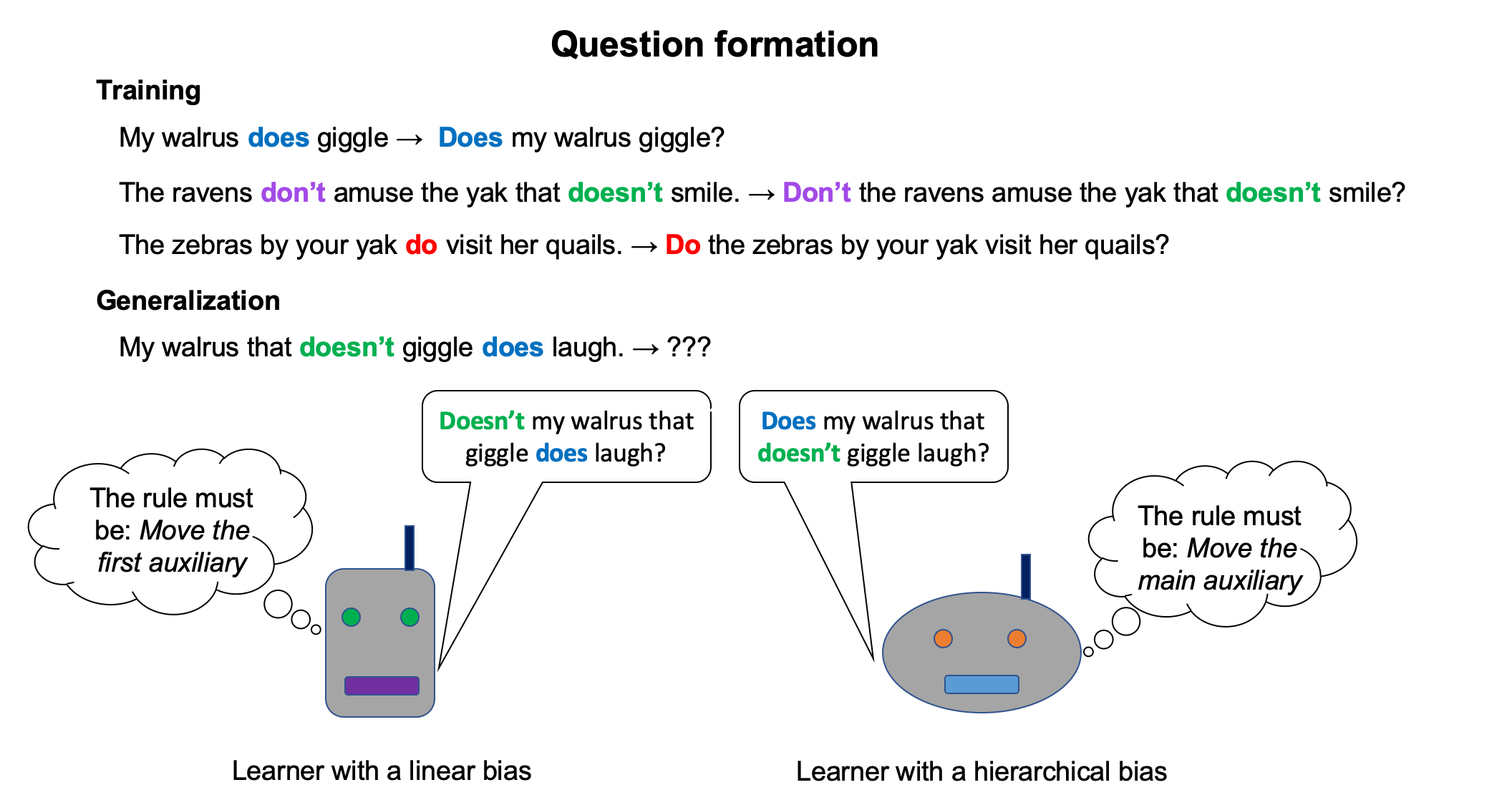
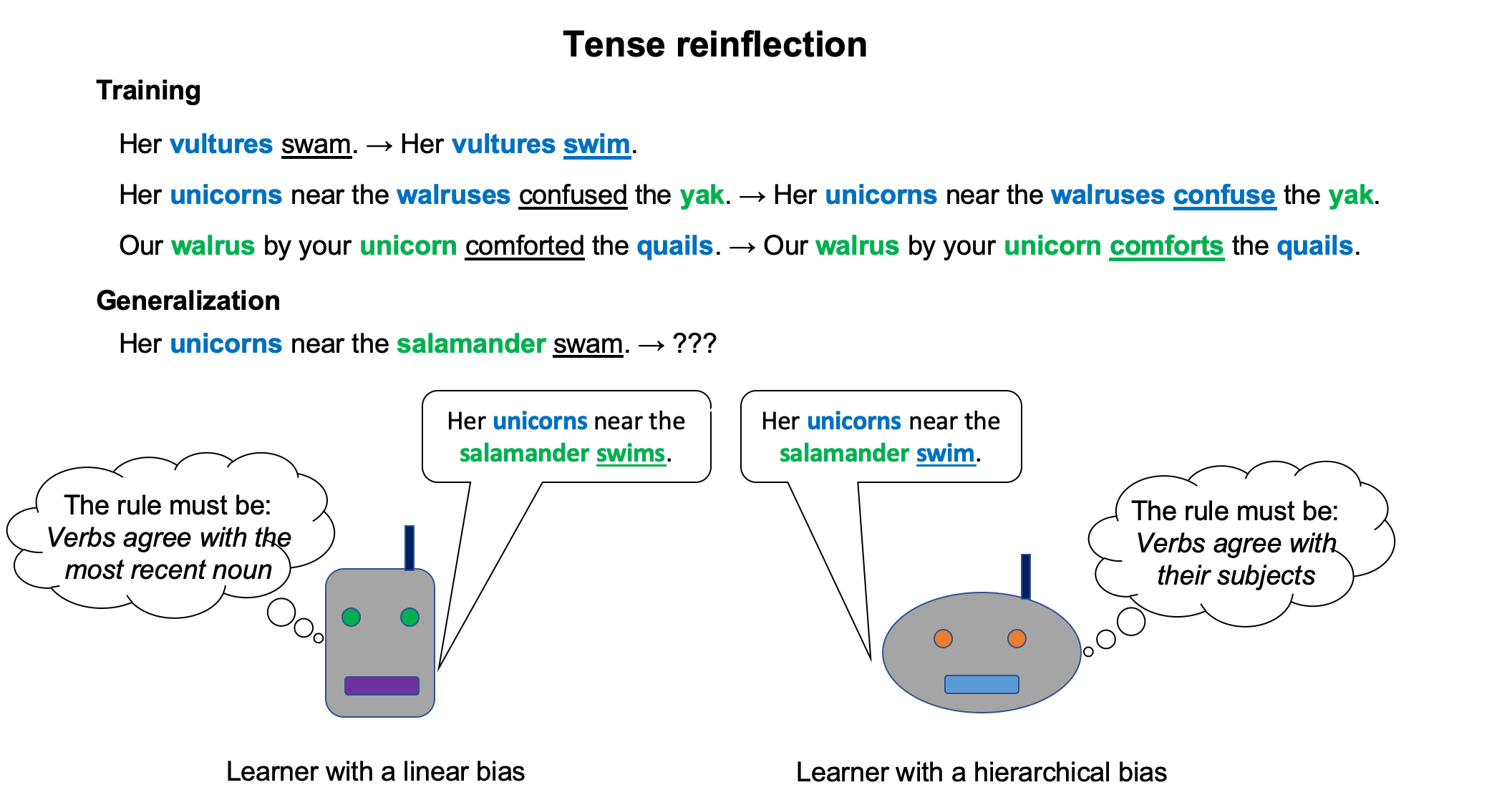
For both of these tasks, we constrain the training set to be consistent with a generalization based on hierarchical structure and a generalization based on linear order. We then evaluate our models on examples that disambiguate these two types of generalizations to see which one each model has learned. If a model behaves consistently with the hierarchical generalization for both tasks, we would then have converging evidence to conclude that the model has a hierarchical bias.
Contents
2. Tasks and evaluation metrics
2.1. Question formation
English question formation involves the movement of an auxiliary verb to the front of the sentence, such as transforming My walrus does giggle into Does my walrus giggle? Simple examples like that one are consistent with two possible rules, a hierarchical rule called Move-Main and a linear rule called Move-First:
- Move-Main: move the main auxiliary to the front of the sentence.
- Move-First: move the first auxiliary to the front of the sentence.
All of our training and evaluation examples are generated from a context-free grammar with a vocabulary size of 75 words. We use this grammar to generate a training set and a test set that are both ambiguous between Move-Main and Move-First as well as a generalization set composed of examples where the two rules make different predictions, such as the following:
- Input declarative sentence: My walrus that doesn't giggle does laugh.
- Prediction of Move-Main: Does my walrus that doesn't giggle ___ laugh?
- Prediction of Move-First: Doesn't my walrus that ___ giggle does laugh?
We use two main evaluation metrics. The first is test set full-sentence accuracy. That is, for examples drawn from the same distribution as the training examples, does the model get the output exactly right, word for word?
For testing generalization to the withheld example type, a natural metric would be full-sentence accuracy on the generalization set. However, in preliminary experiments we found that most models rarely produced the exact output predicted by either Move-Main or Move-First, as they tend to truncate the output, confuse similar words, and make other extraneous errors. To abstract away from such errors, we use generalization set first-word accuracy, which is the proportion of outputs for which the model produced the correct first word. Under both Move-Main and Move-First, the first word of the output is the auxiliary that has been moved from within the sentence. If the main auxiliary and the first auxiliary are different, this word alone is sufficient to distinguish the two rules. For example, in the example above, Move-Main predicts a first word of does while Move-First predicts doesn't. To make this metric valid, therefore, we exclude cases where the two auxiliaries are the same.
There has been a long and lively debate in linguistics about English question formation. Chomsky (1965, 1980) argued that the input to children acquiring English is ambiguous between Move-Main and Move-First but that all English speakers nevertheless acquire Move-Main, which he uses to argue that humans must have a hierarchical bias. Both the empirical basis of this argument and its conclusion have been debated extensively; see our paper for more discussion of the debate. In this work, we do not directly study human language acquisition but instead investigate which computational models have a hierarchical bias so that we can better understand under what conditions learners will learn Move-Main. In the discussion, we will touch on how our findings relate to the debate about human language acquisition.
2.2. Tense reinflection
Our second task, tense reinflection, is the transformation of a past-tense English sentence to a present-tense English sentence, such as turning Her vultures swam into Her vultures swim. The critical part of this task is determining what form the verb should take, as a given past-tense verb in English (such as swam) could be the past tense of either a singular present-tense verb (swims) or a plural present-tense verb (swim). Simple examples such as that one are consistent with two rules, a hierarchical rule called Agree-Subject and a linear rule called Agree-Recent:
- Agree-Subject: a verb agrees with its subject
- Agree-Recent: a verb agrees with the most recent noun before it
We create a training set and a test set that are both ambiguous between Agree-Subject and Agree-Recent as well as a generalization set composed of examples where the two rules make different predictions, such as the following:
- Input declarative sentence: Her unicorns near the salamander swam.
- Prediction of Agree-Subject: Her unicorns near the salamander swim.
- Prediction of Agree-Recent: Her unicorns near the salamander swims.
As with the question-formation task, we evaluate test set performance with test set full-sentence accuracy. For evaluating generalization performance, we use generalization set main-verb accuracy, which is the proportion of outputs for which the main verb was predicted correctly (such as predicting swim instead of swims in the example above.
2.3. Other evaluation metrics
Most of our discussion in this website uses the 3 metrics mentioned above (test set full-sentence accuracy, generalization set first-word accuracy, and generalization set main-verb accuracy), but in case you want to delve deeper into the results we also provide results for several other metrics, which we describe here. If you just want the gist of the website, you can skip this section (or come back to it if there is a particular metric you are interested in), but if you want to read about the other metrics you should click this button to make them visible:
- Metrics used for both tasks:
- Test set full-sentence accuracy: The proportion of test set examples for which the output is exactly correct, word for word.
- Test set full-sentence part-of-speech accuracy: The proportion of test set examples for which the output has the correct sequence of parts of speech. For example, if the correct output is Does the walrus laugh?, this metric would count Doesn't your salamanders run? as correct.
- Generalization set full-sentence accuracy: The proportion of generalization set examples for which the output is exactly correct, word for word.
- Generalization set full-sentence part-of-speech accuracy: The proportion of generalization set examples for which the output has the correct sequence of parts of speech.
- Question formation metrics:
- First-word metrics of accuracy:
- Generalization set: first word = main auxiliary: The proportion of outputs in which the first word is the main auxiliary from the input; e.g., if the input were My walrus that the yaks do see doesn't giggle, this metric would count Doesn't my walrus that the yaks?.
- Generalization set: first word = first auxiliary: The proportion of outputs in which the first word is the first auxiliary from the input; e.g., if the input were My walrus that the yaks do see doesn't giggle, this metric would count Do my walrus that the yaks?. We constrain the generalization set such that the first auxiliary is never the main auxiliary, so any output that satisfies this metric will be incorrect.
- Generalization set: first word = auxiliary not in input: The proportion of outputs in which the first word is an auxiliary that did not appear in the input; e.g., if the input were My walrus that the yaks do see doesn't giggle, this metric would count Don't my walrus that the yaks?.
- Generalization set: first word = non-auxiliary: The proportion of outputs in which the first word is not an auxiliary; e.g., if the input were My walrus that the yaks do see doesn't giggle, this metric would count the my walrus that ravens the yaks?.
- Breakdown by relative clause type: Every sentence in the generalization set has a relative clause modifying its subject, while the training set does not contain any question-formation examples with relative clauses on the subjects. The following metrics break down the generalization set first-word accuracy based on the type of relative clause that is used:
- Generalization set first-word accuracy with object relative clause on subject: The first-word accuracy on the subset of the generalization set where the relative clause modifying the subject is an object relative clause (that is, a relative clause for which the constituent moved out of the relative clause is the object of the verb), such as that the walruses do visit or who my raven doesn't see.
- Generalization set first-word accuracy with transitive subject relative clause on subject: The first-word accuracy on the subset of the generalization set where the relative clause modifying the subject is an subject relative clause (that is, a relative clause for which the constituent moved out of the relative clause is the subject of the verb) with a transitive verb, such as that does visit my walruses or who doesn't see my raven.
- Generalization set first-word accuracy with intransitive subject relative clause on subject: The first-word accuracy on the subset of the generalization set where the relative clause modifying the subject is an subject relative clause (that is, a relative clause for which the constituent moved out of the relative clause is the subject of the verb) with an intransitive verb, such as that does laugh or who doesn't giggle.
- Finer-grained output categorization: Most of the generalization set metrics considered so far only look at the first word of the output, but we use the following metrics to characterize the entire generalization set output. To do so, we frame question formation as having two parts: Placing an auxiliary at the front of the sentence, and deleting an auxiliary from within the sentence. The correct procedure would be to prepose the second auxiliary and also delete the second auxiliary (since, in our particular examples, the second auxiliary is always the main auxiliary), but a model could conceivably follow another procedure such as preposing the first auxiliary and deleting no auxiliary. Here we classify outputs based on which auxiliary was preposed (the first auxiliary, the second auxiliary, or another auxiliary that was not in the input) and which auxiliary was deleted (the first auxiliary, the second auxiliary, or neither):
- Delete first, prepose first: For the input My walrus that does laugh doesn't giggle, this would generate Does my walrus that laugh doesn't giggle?. (This is equivalent to Move-First).
- Delete first, prepose second: For the input My walrus that does laugh doesn't giggle, this would generate Doesn't my walrus that laugh doesn't giggle?.
- Delete first, prepose other: For the input My walrus that does laugh doesn't giggle, this might generate Do my walrus that laugh doesn't giggle?.
- Delete second, prepose first: For the input My walrus that does laugh doesn't giggle, this would generate Does my walrus that does laugh giggle?.
- Delete second, prepose second: For the input My walrus that does laugh doesn't giggle, this would generate Doesn't my walrus that does laugh giggle?. (This is the correct strategy, corresponding to Move-Main).
- Delete second, prepose other: For the input My walrus that does laugh doesn't giggle, this might generate Don't my walrus that does laugh giggle?.
- Delete none, prepose first: For the input My walrus that does laugh doesn't giggle, this would generate Does my walrus that does laugh doesn't giggle?.
- Delete none, prepose second: For the input My walrus that does laugh doesn't giggle, this would generate Doesn't my walrus that does laugh doesn't giggle?.
- Delete none, prepose other: For the input My walrus that does laugh doesn't giggle, this might generate Do my walrus that does laugh doesn't giggle?.
- Other: Many outputs do not fit into any of the above categories and so get thrust into this category of other. Types of errors involved in this category include truncation of the output, swapping a word for another word of the same part of speech (e.g., yak instead of walrus), or changing a relative clause to a prepositional phrase (e.g., if the correct output is Does her salamander that some tyrannosaurus doesn't admire confuse your xylophones below some salamander ?, a model might generate Doesn't her salamander around some tyrannosaurus admire your salamander that does confuse some tyrannosaurus ?).
- Tense reinflection metrics:
- Generalization set full-sentence consistent with agree-recent:The proportion of generalization set outputs that are exactly the output predicted by Agree-Recent. For example, for the input My walrus by the peacocks visited the yak that laughed, this metric would count My walrus by the peacocks visit the yak that laughs.
- Main-verb metrics of accuracy: Note that a particular output may not be counted by any of these four metrics if its sequence of parts of speech is incorrect. In practice, this rarely happens for the tense reinflection task.
- Generalization set: correct main verb (with correct agreement): The proportion of generalization set examples for which the output has the correct sequence of parts of speech and has the correct word in the main verb position (the restriction on parts of speech is imposed so that we can unambiguously identify the position that should be the main verb). For example, if the input is My walrus by the peacocks visited the yak, this metric would count as correct My walrus by the peacocks visits the yak and Some raven near your orangutans visits some quail, but not My walrus visits the yak (wrong sequence of parts of speech) or My walrus by the peacocks visit the yak (wrong number on the main verb).
- Generalization set: correct main verb stem but incorrect agreement: The proportion of generalization set examples for which the output has the correct sequence of parts of speech and has the correct stem in the main verb position but with the incorrect agreement (i.e., the verb is singular when it should be plural, or vice versa). For example, if the input is My walrus by the peacocks visited the yak, this metric would count My walrus by the peacocks visit the yak and Some raven near your orangutans visit some quail, but not My walrus visit the yak (wrong sequence of parts of speech) or My walrus by the peacocks visits the yak (correct number on the main verb).
- Generalization set: correct main verb number The proportion of generalization set examples for which the output has the correct sequence of parts of speech and has the correct number for the word in the main verb position. For example, if the input is My walrus by the peacocks visited the yak, this metric would count My walrus by the peacocks visits the yak and Some raven near your orangutans sees some quail, but not My walrus visits the yak (wrong sequence of parts of speech) or My walrus by the peacocks see the yak (incorrect number on the main verb).
- Generalization set: incorrect main verb number The proportion of generalization set examples for which the output has the correct sequence of parts of speech and has the incorrect number for the word in the main verb position. For example, if the input is My walrus by the peacocks visited the yak, this metric would count My walrus by the peacocks visit the yak and Some raven near your orangutans see some quail, but not My walrus visit the yak (wrong sequence of parts of speech) or My walrus by the peacocks sees the yak (correct number on the main verb).
3. Experiments
The rest of this website gives the complete results for the experiments described in the paper. For each experiment, we ran 100 re-runs of each model involved to control for variation across restarts. Each section contains a table listing the results for all re-runs of all models as well as a boxplot that you can use to visualize the distribution across re-runs (the boxplots display the minimum, the lower fence, the first quartile, the median, the third quartile, the upper fence, the maximum, and any outliers. The upper and lower fences are defined as the points that are 1.5 times the interquartile range outside of the middle 50% of the data). Both the tables and the boxplots can be customized by clicking the buttons near them.
4. Variants of sequential RNNs
4.1. Comparing recurrent units and attention variants

First we trained several types of sequential RNNs on both tasks. The basic structure of this model is illustrated above: First, a component called the encoder reads in the input sequence one word at a time, from left to right, to construct a single vector (E6 in the image) that encodes the input. A second component called the decoder then takes this encoding vector as input, and it outputs one word at a time to create the output, stopping when it generates a punctuation mark. We vary two aspects of the architecture: the recurrent unit (SRN, GRU, or LSTM; the recurrent unit is the component that updates the hidden state of the model from time step to time step), and the type of attention that was used (no attention, location-based attention, or content-based attention; attention is a mechanism that allows the decoder to peek back at the encoder). The table and boxplot below show the effects of these factors.
Use these buttons to select which task/model combinations will be displayed in the table and plot:
🚫 stands for no attention, 🌎 stands for location-based attention, and 📖 stands for content-based attention
Takeaways from these experiments:
- For both tasks, the SRN without attention fails at the test set, with a test set full-sentence accuracy consistently at 0%. However, its test set full-sentence part of speech accuracy is always high, suggesting that its main error is confusing words that have the same part of speech. (click here to see question formation results in the plot, click here to see tense reinflection results in the plot) This is corroborated by inspecting some of this model type's outputs in the table; for example, when the correct output was "her unicorn doesn't entertain her yak .", the model instead returned "my vulture doesn't entertain my peacock ." (click here to see question formation outputs in the table, click here to see tense reinflection outputs in the table.) Frank and Mathis (2007) observed similar error patterns for SRNs without attention.
- All other model types had high test-set full-sentence accuracy on both tasks, showing that they have mastered the types of examples they have been trained on. (click here to see question formation results in the plot, click here to see tense reinflection results in the plot)
- Our main question relates to how models generalize, so the most important results to consider are results on the generalization set. First, note that there is considerable generalization variability across reruns of the same model; e.g., the SRN with content-based attention had generalization set first-word accuracy ranging from 0.17 to 0.90 (click here to see in the plot) (cf. McCoy, Min, and Linzen (2019), who also found extreme generalization variability in neural models). To understand models' typical behavior, therefore, we mainly consider the median across all 100 initializations.
- Considering the median first-word generalization accuracy for the question formation task, we see that the type of recurrent unit can have a dramatic effect; for example, among models with location-based attention, all three models had very different ranges of accuracy (click here to see in the plot). The type of attention can also have a dramatic effect; e.g., GRUs with different types of attention had very different ranges of accuracy (click here to see in the plot).In addition to the recurrent unit and the attention having substantial effects on their own, it also appears that the interactions of these factors are important. For example, in GRUs, location-based attention led to performance more consistent with Move-Main and content-based attention led to performance more consistent with Move-First, but these types of attention had opposite effects in SRNs (click here to see in the plot).
- There are two models that exhibited a preference for Move-Main over Move-First, as evidenced by having a median first-word generalization set accuracy above 50% (which is chance): The SRN with content-based attention and the GRU with location-based attention.(click here to see in the plot). We do not know why these two models in particular behave this way.
- When we take a closer look, there is reason to believe that these models have not actually learned hierarchical transformations. The bullets above only considered first-word accuracy on the generalization set, as the full-sentence outputs are often messy. However, if we do look at the specific types of outputs given by the GRU with location-based attention, we see that its most common categorizable output type is delete none, prepose second—which is hierarchical in nature and is therefore not a problem. However, it does often have outputs of types that cannot be considered fully hierarchical, such as delete first, prepose second (e.g., transforming My walrus that does laugh doesn't giggle into Doesn't my walrus that laugh doesn't giggle?). The deletion of the first auxiliary is not hierarchically-based, suggesting that these models have not learned a truly hierarchical generalization (click here to see in the plot)
- As for the SRN with content-based attention, we see that it almost always gets the right first auxiliary when the relative clause modifying the subject is a subject relative clause, but almost always gets the wrong auxiliary when it is an object relative clause. The internal structure of this relative clause should not matter to the question formation process, so the fact that it does matter suggests that this model category has learned some heuristic rather than the correct Move-Main rule. (click here to see in the plot)
- Perhaps most importantly, all of these models—including the 2 that showed somewhat hierarchical behavior on question formation—behaved very linearly with tense reinflection; ignoring the SRN without attention (whose problems were discussed earlier), all models almost always have the linear main verb (click here to see in the plot), and even the full output sentence is often the exact sentence predicted by agree-recent (click here to see in the plot). This fact suggests that none of these 9 model types have a hierarchical bias, because if they had such a bias it should apply across training tasks; whereas we only saw behavior consistent with a hierarchical bias at all with question formation, and even there it is arguable, as discussed in the above bullets.
- What did drive the preference for Move-Main that we observed in two models (the SRN with content-based attention and the GRU with location-based attention), if it was not a hierarchical bias? We don't know; however, other work has suggested that n-gram statistics could drive a preference for Move-Main over Move-First (Kam et al. 2008, Berwick et al. 2011), so it is possible that these models are just manifesting a bias to focus on n-grams, which is a bias that sequential neural networks seem intuitively likely to have. Indeed, such a bias would also be consistent with the poor tense reinflection performance that we observed across all models, because bigram statistics would strongly favor the wrong generalization for tense reinflection (Agree-Recent rather than Agree-Subject), because making a generalization that is consistent with Agree-Subject requires generating bigrams that have never been seen before, such as vultures amuses in the quail near your vultures amuses your yak, whereas the outputs predicted by Agree-Recent would never require novel bigrams.
4.2. Effects of squashing
One striking result in the previous section is that LSTMs and GRUs display qualitative differences, even though the two architectures are often viewed as interchangeable and achieve similar performance in applied tasks (Chung et al., 2014). One difference between LSTMs and GRUs is that a squashing function is applied to the hidden state of a GRU to keep its values within the range (−1,1), while the cell state of an LSTM is not bounded. Weiss et al. (2018) demonstrate that such squashing leads to a qualitative difference in how well these models generalize counting behavior. Such squashing may also explain the qualitative differences that we observe: counting the input elements is equivalent to keeping track of their linear positions, so we might expect that a tendency to count would make the linear generalization more accessible.
To test whether squashing increases a model’s preference for Move-Main, we created a modified LSTM that included squashing in the calculation of its cell state, and a modified GRU that did not have the squashing usually present in GRUs. Results for these models, as well as for the standard variants of the GRU and LSTM, are below.
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- For both GRUs (click here to see in the plot) and LSTMs (click here to see in the plot), the version with squashing had a much higher generalization set first-word accuracy than the version without squashing, suggesting that the squashing may be one major reason for the differences observed between these two types of recurrent units.
- However, it's also true that the squashed GRU outperforms the squashed LSTM (click here to see in the plot), and the unsquashed GRU outperforms the unsquashed LSTM (click here to see in the plot). Therefore, there must also be other factors in besides the squashing that lead to differences between GRUs and LSTMs.
4.3. Learning rate and hidden size
We searched over 2 hyperparameters, learning rate and hidden size, for the question formation task. We do not have hypotheses about how the learning rate would be relevant for this task, but there are plausible reasons why hidden size might matter: a smaller hidden size might force a model to learn more compact representations, which would lead to a bias for generalizations that can be described efficiently. For a language that can be most compactly described in hierarchical terms, such a bias would favor Move-Main (Perfors et al., 2011). On the other hand, the sequential structure of our model is closer to the linear structure underlying Move-First than the tree structure underlying Move-Main. Thus, a more compressed hidden state might bias a sequential model toward Move-First by giving it less capacity to develop a representation that deviates from its own structure. The following plots show results of these explorations:
This table shows how generalization set first-word accuracy varies with hidden size (each cell is a median over 10 restarts; 🚫 stands for no attention, 🌎 stands for location-based attention, and 📖 stands for content-based attention):

From this table, it appears that, for GRUs with location-based attention, greater hidden sizes are associated with higher scores. To test this more systematically, we ran 1 experiment for each of 100 hidden sizes (namely hidden sizes 60, 63, 66, ... , 354, 357), and found that there was indeed a significant positive correlation (Spearman's correlation coefficient = 0.62; p < 10e-11):
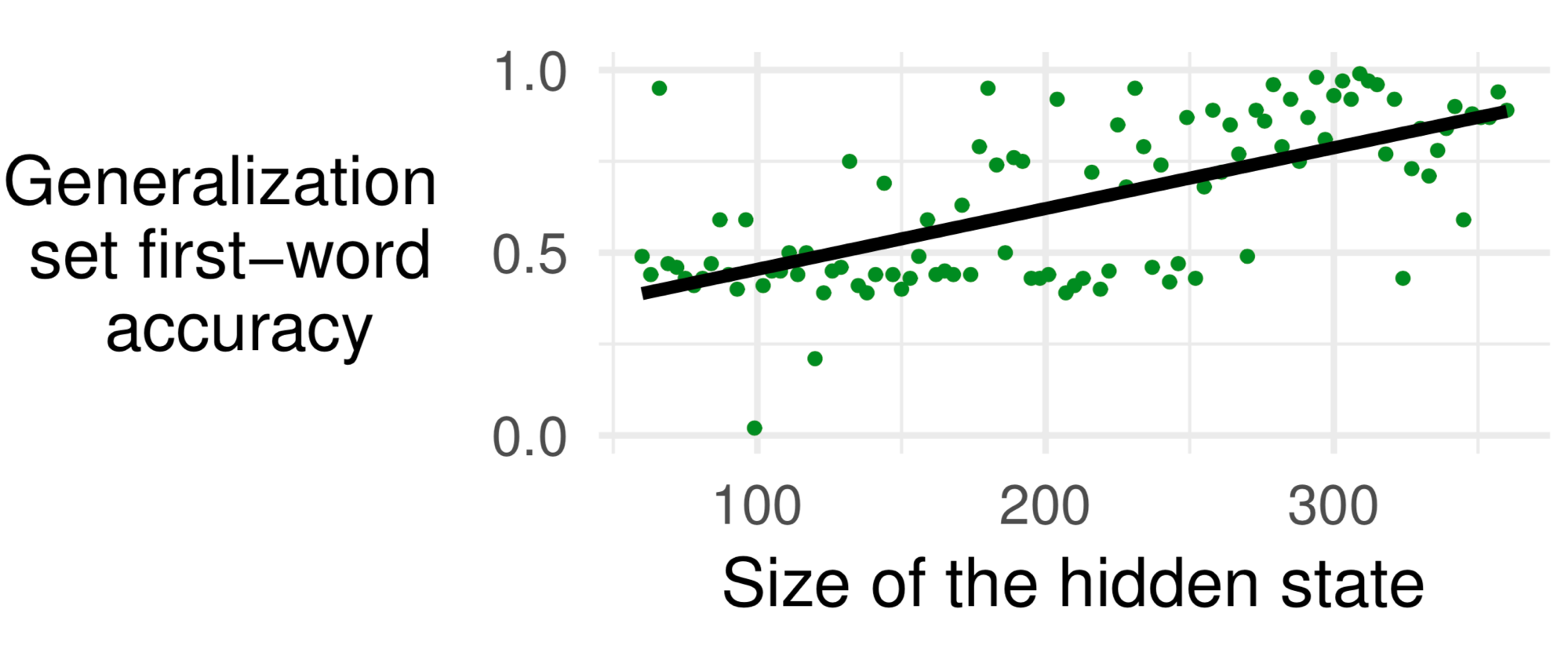
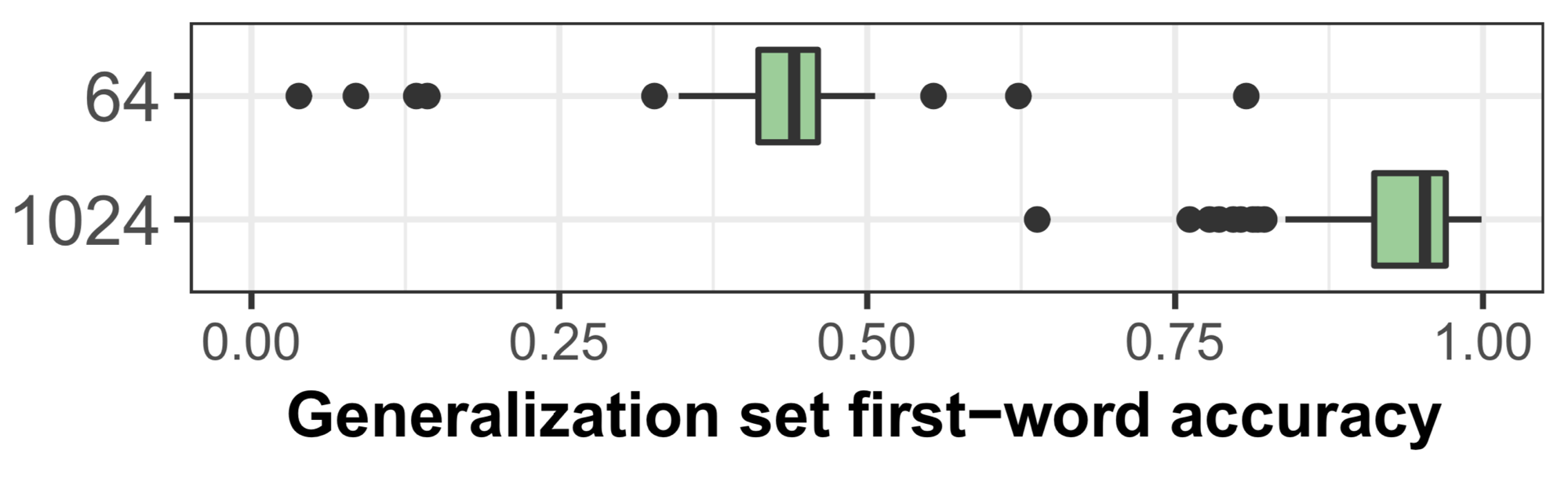
Moreover, this correlation cannot be attributed to overall stronger performance, since test set full-sentence accuracy was negatively correlated with hidden size (Spearman's correlation coefficient = -0.56). We further ran 100 iterations for each of two hidden sizes, namely 64 and 1024, and also found a noticeable difference between the two:
This table shows how generalization set first-word accuracy varies with learning rate (each cell is a median over 10 restarts; 🚫 stands for no attention, 🌎 stands for location-based attention, and 📖 stands for content-based attention):
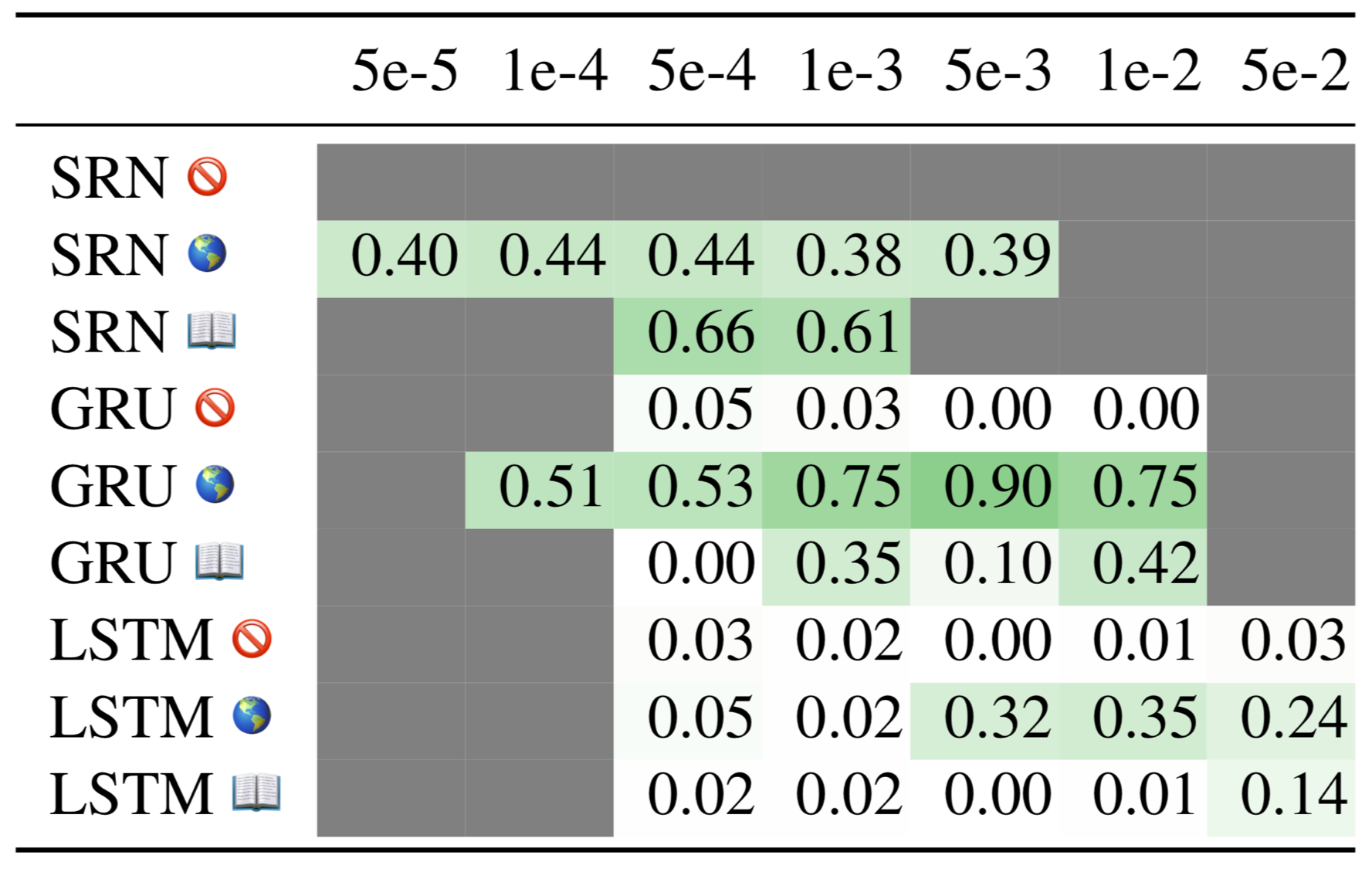
From this table, it appears that, for GRUs with location-based attention, greater learning rates are associated with higher scores. To test this more systematically, we ran 1 experiment for each of 100 learning rates (namely learning rates of 0.00010, 0.00012, 0.00014, ... , 0.00206, 0.00208), and found that there was indeed a significant positive correlation (Spearman's correlation coefficient = 0.42; p < 10e-4):
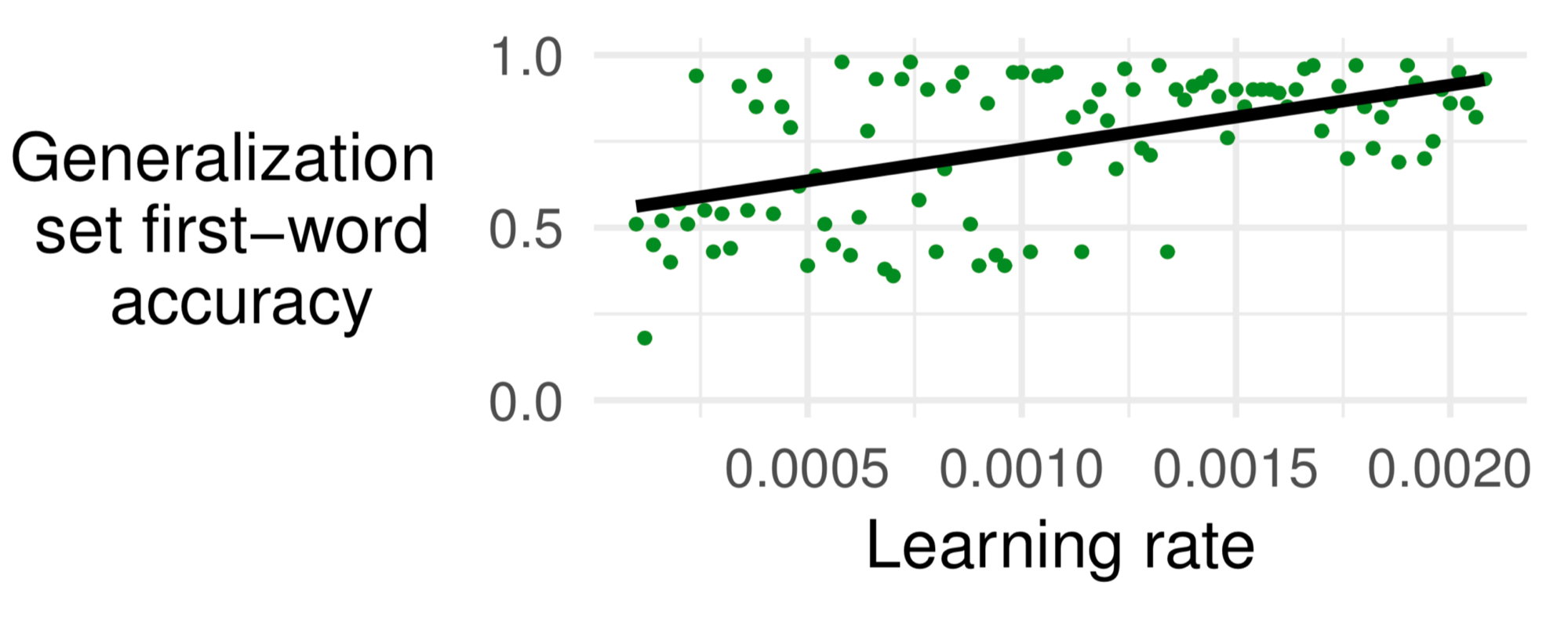
Learning rate is also positively correlated with test set full-sentence accuracy; however, a likelihood ratio test shows that learning rate significantly predicts generalization set first-word accuracy beyond the effects of test set full-sentence accuracy (p < 10e−4).We further ran 100 iterations for each of two learning rates, namely 0.005 and 0.0005, and also found a noticeable difference between the two:
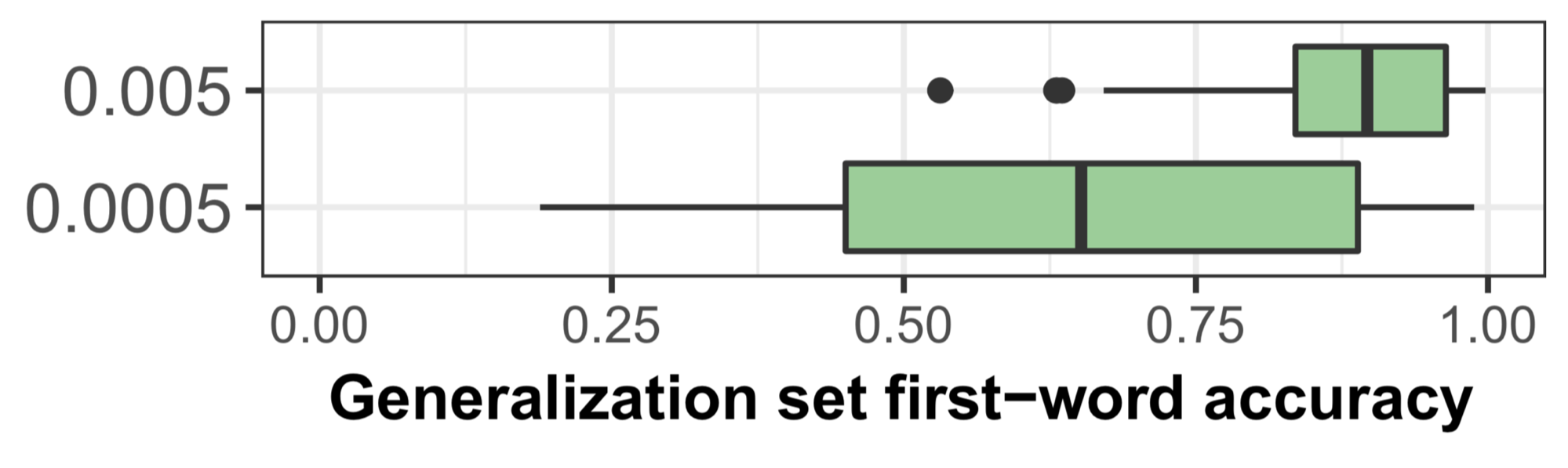
This table gives the results for all model instances trained for this section.
5. Tree-based models
5.1. Tree-based recurrent units
So far we have tested whether properties that are not interpretably related to hierarchical structure nevertheless affect how a model generalizes on syntactic tasks. The basic finding is that all of the factors we tested (recurrent unit, type of attention, learning rate, and hidden size) can significantly affect a model's generalization behavior, but none of the models we tested appear to have a true hierarchical bias. We now turn to a related but opposite question: when a model’s design is meant to give it a hierarchical inductive bias, does this design succeed at giving the model this bias?
To investigate this question, we now compare two tree-based recurrent units (the Ordered Neurons model (ON-LSTM) and a Tree-GRU) to the sequential recurrent units used above, all without attention. The ON-LSTM is structured in a way intended to lead to the implicit construction of a parse tree in the model's cell state; the Tree-GRU is explicitly built around a tree structure that is provided to the model.
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- The Ordered Neurons model, like all of the sequential models, strongly preferred both linear generalizations: Move-First for question formation, and Agree-Recent for tense reinflection. This suggests that, although this model's architecture was motivated by hierarchical structure, it does not have a hierarchical bias. This finding is consistent with Dyer et al. (2019). (click here to see question formation results in the plot, click here to see tense reinflection results in the plot)
- The Tree-GRU, however, does display a strong preference for the hierarchical generalization on both question formation (click here to see in the plot) and tense reinflection (click here to see in the plot), suggesting that it does have a hierarchical bias.
- The Tree-GRU stands out in another way as well: It also achieves reasonably high full-sentence accuracy on the generalization set. (click here to see question formation results in the plot, click here to see tense reinflection in the plot)
5.2. Effect of encoder and decoder
All of the models we use have two components, the encoder and the decoder. So far we have only tested models where the encoder type and the decoder type match, and this has shown that models where both components are explicitly built around trees will generalize hierarchically but models where both components are sequential will not.
Is this difference between tree-based models and sequential models due to the encoder, the decoder, or both? Here we test this using a model whose encoder is a sequential GRU but whose decoder is a Tree-GRU and a model whose encoder is a Tree-GRU but whose decoder is a sequential GRU (as well as two models from before: the model with a sequential GRU encoder and sequential GRU decoder, and the model with a Tree-GRU encoder and a Tree-GRU decoder).
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- Both models with a tree-based decoder generalized hierarchically, while both models with a sequential decoder (even the model with a Tree-GRU encoder and a sequential decoder) generalized linearly. This suggests that it is the decoder that is more important, a finding consistent with McCoy et al. (2019) who found that the nature of the representation learned by a sequence-to-sequence RNN is mainly determined by the structure of the decoder rather than the encoder. (click here to see in the plot)
- Of the two models with a tree-based decoder, only the model that also had a tree-based encoder achieved high full-sentence accuracy on the test set; the model with a GRU encoder and Tree decoder usually performed poorly on the test set, so the only model that performed well on the test set and generalized hierarchically was the model with a tree-based encoder and a tree-based decoder. However, some of the GRU/Tree models did perform well, so it is possible that we would get better test-set performance from this model if we trained it with a greater patience than we used for other models, to help it overcome the mismatch between its encoder and decoder. (click here to see in the plot)
6. Are tree models constrained to generalize hierarchically?
It may seem that the tree-based models are constrained by their structure to make only hierarchical generalizations, rendering their hierarchical generalization trivial. In this section, we test whether they are in fact constrained in this way, and similarly whether sequential models are constrained to make only linear generalizations.
Earlier, the training sets for our two tasks were ambiguous between two generalizations, but we now used training sets that unambiguously supported either a linear transformation or a hierarchical transformation. For example, we used a Move-Main training set that included some examples like My walrus that does laugh doesn't giggle turning into Doesn't my walrus that does laugh giggle?, while the Move-First training set included some examples like My walrus that does laugh doesn't giggle turning into Does my walrus that laugh doesn't giggle?. Similarly, for the tense reinflection task, we created an Agree-Subject training set and an Agree-Recent training set. For each of these four training sets, we trained 100 sequential GRUs and 100 Tree/Tree GRUs, all without attention. Results are below.
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- Both the sequential GRU and the Tree-GRU achieved high accuracy on all datasets (click here to see question formation results in the plot, click here to see tense reinflection results in the plot).
- Perhaps more important than the high accuracy is the consistency across tasks: On both question-formation datasets, the tree-based model got 96% full-sentence accuracy on the test set (click here to see in the plot), and on both tense-reinflection datasets it got 95% (click here to see in the plot). The sequential GRU got 87% full-sentence accuracy on both question formation datasets (click here to see in the plot) and 89% full-sentence accuracy on both tense reinflection datasets (click here to see in the plot). These results show that both types of models are equally capable of learning hierarchically-based rules and sequentially-based rules; thus, the preferences we have observed above (that is, the preference of sequential models for linear generalizations and the preference of tree models for hierarchical generalizations) are biases rather than constraints.
7. Tree structure vs. tree information
Our sequential and tree-based models differ not only in structure but also in the information they have been provided: the tree-based models have been given correct parse trees for their input and output sentences, while the sequential models have not been given parse information. Therefore, it is unclear whether the hierarchical generalization displayed by the tree-based models arose from the tree-based model structure, from the parse information provided to the models, or both.
To disentangle these factors, we ran two further experiments. First, we retrained the Tree/Tree GRU but using uniformly right-branching trees instead of correct parses. Thus, these models make use of tree structure but not the kind of parse structure that captures linguistic information. Second, we retrained the sequential GRU without attention but modified the input and output by adding brackets that indicate each sentence’s parse. Thus, these models are provided with parse information in the input but such structure does not guide the neural network computation as it does with tree RNNs. Results for these experiments are below (along with results for sequential GRUs without brackets in the input, and tree RNNs given the correct parses).
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- On tense reinflection, adding brackets to the GRU's input had little discernible effect; if anything it gave it an even stronger sequential preference (possibly because adding brackets increased the distance between the verb and its subject).(click here to see in the plot)
- On question formation, adding brackets did improve its generalization. However, it remains below chance (50%), so these brackets were still not enough to give it hierarchical generalization despite pushing it in that direction.(click here to see in the plot)
- On both tasks, the Tree-GRU give right-branching trees generalized poorly. (click here to see question formation results in the plot, click here to see tense reinflection results in the plot)
- These results show two things:
- The failure of the brackets in the input to lead models to generalize hierarchically shows that giving a model parse information alone is insufficient; the tree structure must be built into the model's computations, as it is in the Tree-GRU.
- However, it is not enough to just have any trees built in, as the Tree-GRU with right-branching trees shows; the model must have the correct trees.
8. Multitask learning
Each experiment discussed so far involved a single linguistic transformation. By contrast, humans acquiring language are not exposed to phenomena in isolation but rather to a complete language encompassing many phenomena. This fact has been pointed to as a possible way to explain hierarchical generalization in humans without needing to postulate any innate preference for hierarchical structure. While one phenomenon, such as question formation, might be ambiguous in the input, there might be enough direct evidence among other phenomena to conclude that the language as a whole is hierarchical, a fact which learners can then extend to the ambiguous phenomenon (Pullum and Scholz, 2002; Perfors et al., 2011), under the non-trivial assumption that the learner will choose to treat the disparate phenomena in a unified fashion. Therefore, perhaps a training setup that includes more phenomena than just a single ambiguous one can lead to better generalization on the ambiguous phenomenon.
To take a first step toward investigating this possibility, we use a multi-task learning setup, where we train a single model to perform both question formation and tense reinflection. We set up the training set such that one task was unambiguously hierarchical while the other was ambiguous between the hierarchical generalization and the linear generalization. This gave two settings: One where question formation was ambiguous, and one where tense reinflection was ambiguous. In addition, one major way in which the two tasks differ is that all question formation examples use auxiliary verbs (e.g., My walrus does giggle) while all tense reinflection sentences use inflected verbs (e.g., My walrus giggles). In case this disparity makes the tasks too different to enable cross-phenomenon generalization, we also created a condition of multi-task learning with auxiliary verbs added to the tense reinflection examples to make them more similar to question formation. We trained 100 instances of a GRU without attention on each setting and assessed how each model generalized for the task that was ambiguous.
Use these buttons to select which task/model combinations will be displayed in the table and plot:
Takeaways from these experiments:
- For both tasks, the simple multitask setup performed slightly better than the single-task setup, but not by a major amount, and also not enough to move its median above the chance level of 50%, which is our criterion for hierarchical generalization. (click here to see question formation results in the plot, click here to see tense reinflection results in the plot)
- Adding auxiliaries to the tense reinflection multitask had little effect on transfer from tense reinflection to question formation (click here to see in the plot); however, it did majorly improve the transfer from question formation to tense reinflection (click here to see in the plot).
- However, this improvement likely arises for uninteresting reasons: The question formation dataset includes unambiguous long-distance subject-verb agreement as in the sentence My zebras by the yak do read. Therefore, the inclusion of such sentences is likely what leads to the improvement on tense reinflection, rather than any sort of generalization from one syntactic transformation to another.
- Therefore, it appears that our models are unlikely to generalize hierarchical strategies from one phenomenon to another. This result is consistent with findings that neural models trained on multiple tasks will learn largely independent representations across tasks even when a unified representation could be used (Kirov and Frank, 2011). However, humans might have a stronger bias than these models do for treating multiple phenomena in a unified way.
9. Conclusion
9.1. Main takeaways
We have found that all factors we tested can qualitatively affect a model’s inductive biases but that a hierarchical bias—which has been argued to underlie children’s acquisition of syntax—only arose in a model whose inputs and computations were governed by syntactic structure.
9.2. Relation to human language acquisition
Our experiments showed that some tree-based models displayed a hierarchical bias, while non-tree-based models never displayed such a bias, even when provided with strong cues to hierarchical structure in their input (through bracketing or multi-task learning). These findings suggest that the hierarchical preference displayed by humans when acquiring English requires making explicit reference to hierachical structure, and cannot be argued to emerge from more general biases applied to input containing cues to hierarchical structure.
Moreover, since the only successful hierarchical model was one that took the correct parse trees as input, our results suggest that a child’s set of biases includes biases governing which specific trees will be learned. Such biases could involve innate knowledge of likely tree structures, but they do not need to; they might instead involve innate tendencies to bootstrap parse trees from other sources, such as prosody (Morgan and Demuth, 1996) or semantics (Pinker, 1996). With such information, children might learn their language’s basic syntax before beginning to acquire question formation, and this knowledge might then guide their acquisition of question formation.
There are three important caveats for extending our conclusions to humans.
- Humans may have a stronger bias to share processing across phenomena than neural networks do, in which case multi-task learning would be a viable explanation for the biases displayed by humans even though it had little effect on our models. Indeed, this sort of cross-phenomenon consistency is similar in spirit to the principle of systematicity, and it has long been argued that humans have a strong bias for systematicity while neural networks do not (e.g., Fodor and Pylyshyn, 1988; Lake and Baroni, 2018).
- Some have argued that children’s input actually does contain utterances unambiguously supporting a hierarchical transformation (Pullum and Scholz, 2002), whereas we have assumed a complete lack of such examples.
- Our training data omit many cues to hierarchical structure that are available to children, including prosody and real-world grounding. It is possible that, with data closer to a child’s input, more general inductive biases might succeed.
However, there is still significant value in studying what can be learned from strings alone, because we are unlikely to understand how the multiple components of a child’s input interact without a better understanding of each component. Furthermore, during the acquisition of abstract aspects of language, real-world grounding is not always useful in the absence of linguistic biases (Gleitman and Gleitman, 1992). More generally, it is easily possible for learning to be harder when there is more information available than when there is less information available (Dupoux, 2018). Thus, our restricted experimental setup may actually make learning easier than in the more informationally-rich scenario faced by children.
9.3. Practical takeaways
Our results leave room for three possible approaches to imparting a model with a hierarchical bias.
First, one could search the space of hyperparameters and random seeds to find a setting that leads to the desired generalization. However, this may be ineffective: At least in our limited exploration of these factors, we did not find a hyperparameter setting that led to hierarchical generalization across tasks for any non-tree-based model. A more principled search, such as one using meta-learning, might be more promising.
A second option is to add a pre-training task or use multi-task learning (Caruana, 1997; Collobert and Weston, 2008; Enguehard et al., 2017), where the additional task is designed to highlight hierarchical structure. Most of our multi-task experiments only achieved modest improvements over the single-task setting, suggesting that this approach is also not very viable. However, it is possible that further secondary tasks would bring further gains, making this approach more effective.
A final option is to use more interpretable architectures with explicit hierachical structure. Our results suggest that this approach is the most viable, as it yielded models that reliably generalized hierarchically. However, this approach only worked when the architectural bias was augmented with rich assumptions about the input to the learner, namely that the input provided correct hierarchical parses for all sentences. We leave for future work an investigation of how to effectively use tree-based models without providing correct parses.
Questions? Comments? Email tom.mccoy@jhu.edu.